【Python】USDJPYデータをRandomForestRegressorで解析したけどMSEは高得点・R²は低評価:原因と今後の方針
僕は最近、USDJPYの1時間足データを解析し、RandomForestRegressorを使って値動きを予測するモデルを試しました。データに新しい特徴量を追加し、result24(24時間後の値動き)を目的変数に設定しました。学習後の評価ではMSEが0.845と比較的高スコアを記録しましたが、テスト値と予測値の相関係数R²が0.0832と非常に悪い結果になり、予測性能に大きな課題があることが判明しました。
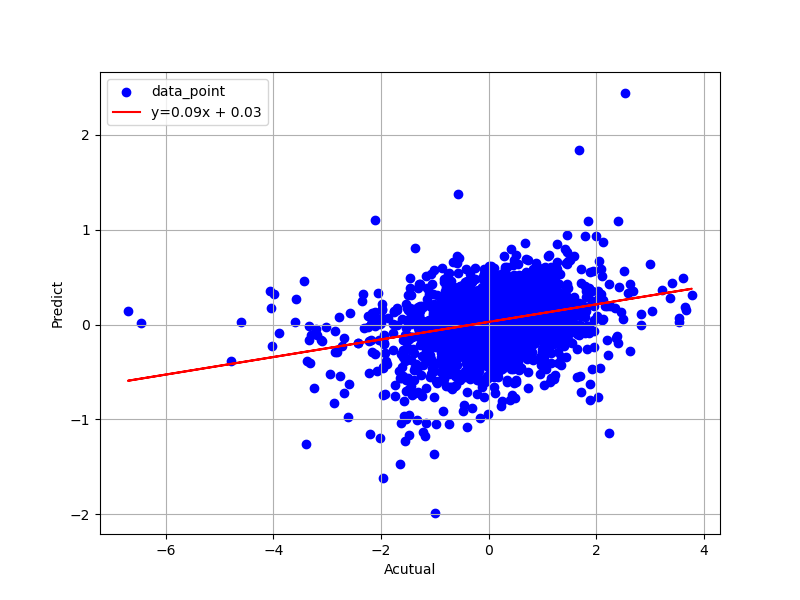
Python/scikit-learnから生成したテスト値と予測値との関係
こちらがPython/scikit-learnから生成したテスト値と予測値との関係(散布図)です。ソースコードは後ほど。
傾きが0.09と小さく、出力された相関係数も0.0832と相関性があるとは言えない結果でした。一方で出力された評価指標(MSE)は0.845と割と高スコア。。。いったいどういうことでしょうか。
現状の問題点まとめ
相関が低い理由
目的変数であるresult24は、特徴量と非線形な関係がある可能性があります。この関係をモデルが十分に捉えられていないのかもしれません。
特徴量の選定
ローソク足の高さや移動平均、傾きなどの特徴量を追加しましたが、本当にresult24との関連性が強いかどうかは精査が必要です。
時間差の影響
24時間という長めの予測時間を取ったため、短期的な値動きの影響が薄れている可能性があります。
今後の学習方針
特徴量エンジニアリングの見直し
- result24(目的変数)に強い影響を与えそうな新しい特徴量を追加する。例として、ボラティリティやRSIなどのテクニカル指標の導入。
- 現在の特徴量の重要度を分析し、不必要な特徴を削除してモデルの精度を向上させる。
予測ターゲットの変更
- 現在は24時間後の値動きを予測していますが、短期(例:1時間後、6時間後)での予測に切り替え、モデルの理解度を向上させる。
モデル選定の拡張
- RandomForestRegressor以外にも、非線形性に強いGradient Boosting Machines(例:XGBoost, LightGBM)やニューラルネットワークを試してみる。
データの拡充
- より長い期間のデータや、USDJPY以外の通貨ペアを含めた多様なデータセットを活用して汎化性能を高める。
僕自身、今回の結果は少し残念でしたが改善の余地はまだまだあると思っています。引き続き試行錯誤を続け次回はより良い結果をお届けできるよう頑張ります!
今回のソースコード
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
import numpy as np
import pandas as pd
df = pd.read_csv('usdjpy_result.csv')
# Date列を除いたデータ
X = df.drop(columns=['Date', 'result24'])
y = df['result24']
# データの分割(訓練データとテストデータ)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 標準化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# モデルの訓練
model = RandomForestRegressor(random_state=42, n_estimators=100)
model.fit(X_train_scaled, y_train)
# テストデータでの予測
y_pred = model.predict(X_test_scaled)
# 評価指標(MSE)の計算
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
print(mse, rmse)
df = pd.DataFrame({
'y_test': y_test,
'y_pred': y_pred
})
df.to_csv('predict.csv', index=False, encoding='utf-8')
各指標(特徴量と目的変数)の解説
以下に、ソースコードで算出した各指標について解説します。
特徴量
- CandleHeight (ローソクの高さ):計算式: df[‘Close’] – df[‘Open’]
- UpperWick (上ヒゲの高さ):計算式: df[‘High’] – df[[‘Close’, ‘Open’]].max(axis=1)
- LowerWick (下ヒゲの高さ):計算式: df[[‘Close’, ‘Open’]].min(axis=1) – df[‘Low’]
- MA_5 (5期間移動平均):計算式: df[‘Close’].rolling(window=5).mean()
- MA_25 (25期間移動平均):計算式: df[‘Close’].rolling(window=25).mean()
- Slope_Close (終値の傾き):過去10ポイントの終値を線形回帰し、その傾きを計算。np.polyfit関数を使って価格データを直線にフィッティング。
- Slope_MA5, Slope_MA25 (移動平均線の傾き):5期間および25期間移動平均について、過去10ポイントの傾きを計算。
- MA_Signal (移動平均の交差信号):短期移動平均線(MA_5)が長期移動平均線(MA_25)より上なら1、下なら-1、等しい場合は0。隣接する値を2つの平均で平滑化。ゴールデンクロス(買いシグナル)やデッドクロス(売りシグナル)を数値で表現したもの。
- CloseMA5_Height, CloseMA25_Height (移動平均線と終値の差):df[‘MA_5’] – df[‘Close’]、df[‘MA_25’] – df[‘Close’]
- MA_Height (短期移動平均と長期移動平均の差):df[‘MA_5’] – df[‘MA_25’]
- MA_Integral (移動平均の積分値):MA_Heightの値を累積。クロス(MA_Heightが0を通過する場合)でリセット。
目的変数
- result24 (24時間後の値動き):計算式: df[‘Close’].shift(-24) – df[‘Close’]
各指標を組み合わせることで価格変動やトレンドの特徴を多角的に捉え、予測モデルの学習に役立てることが期待されます。ただし、これらの指標が目的変数にどれだけ関連しているかの確認が今後の重要なステップです。
スポンサーリンク